Vue3.0的优化
vue1.0 到 vue2.0最大的升级就是引入了虚拟 DOM 的概念,它为后续做服务端渲染以及跨端框架 Weex 提供了基础。
1、源码优化
源码的优化主要体现在使用 monorepo 和 TypeScript 管理和开发源码,这样做的目标是提升自身代码可维护性。
monorepo
本质上从以前把所有代码根据模块放置在src目录下改成了分成不同的项目放在packages下,每个 package 有各自的 API、类型定义和测试。这样使得模块拆分更细化,职责划分更明确,模块之间的依赖关系也更加明确,开发人员也更容易阅读、理解和更改所有模块源码,提高代码的可维护性。
另外一些 package(比如 reactivity 响应式库)是可以独立于 Vue.js 使用的,这样用户如果只想使用 Vue.js 3.0 的响应式能力,可以单独依赖这个响应式库而不用去依赖整个 Vue.js,减小了引用包的体积大小,而 Vue.js 2 .x 是做不到这一点的。
用TypeScript开发
Vue.js 3.0 抛弃 Flow 后,使用 TypeScript 重构了整个项目。 TypeScript提供了更好的类型检查,能支持复杂的类型推导;由于源码就使用 TypeScript 编写,也省去了单独维护 d.ts 文件的麻烦;就整个 TypeScript 的生态来看,TypeScript 团队也是越做越好,TypeScript 本身保持着一定频率的迭代和更新,支持的 feature 也越来越多。
2、性能优化
源码体积优化
移除了一些冷门feature(filter、inline-template等)
引入tree-shaking,减少打包体积。
tree-shaking 依赖 ES2015 模块语法的静态结构(即 import 和 export),通过编译阶段的静态分析,找到没有引入的模块并打上标记。
webpack打包好的文件会标记上没有被引用的代码块,然后压缩阶段会利用例如 uglify-js、terser 等压缩工具真正地删除这些没有用到的代码。
数据劫持优化
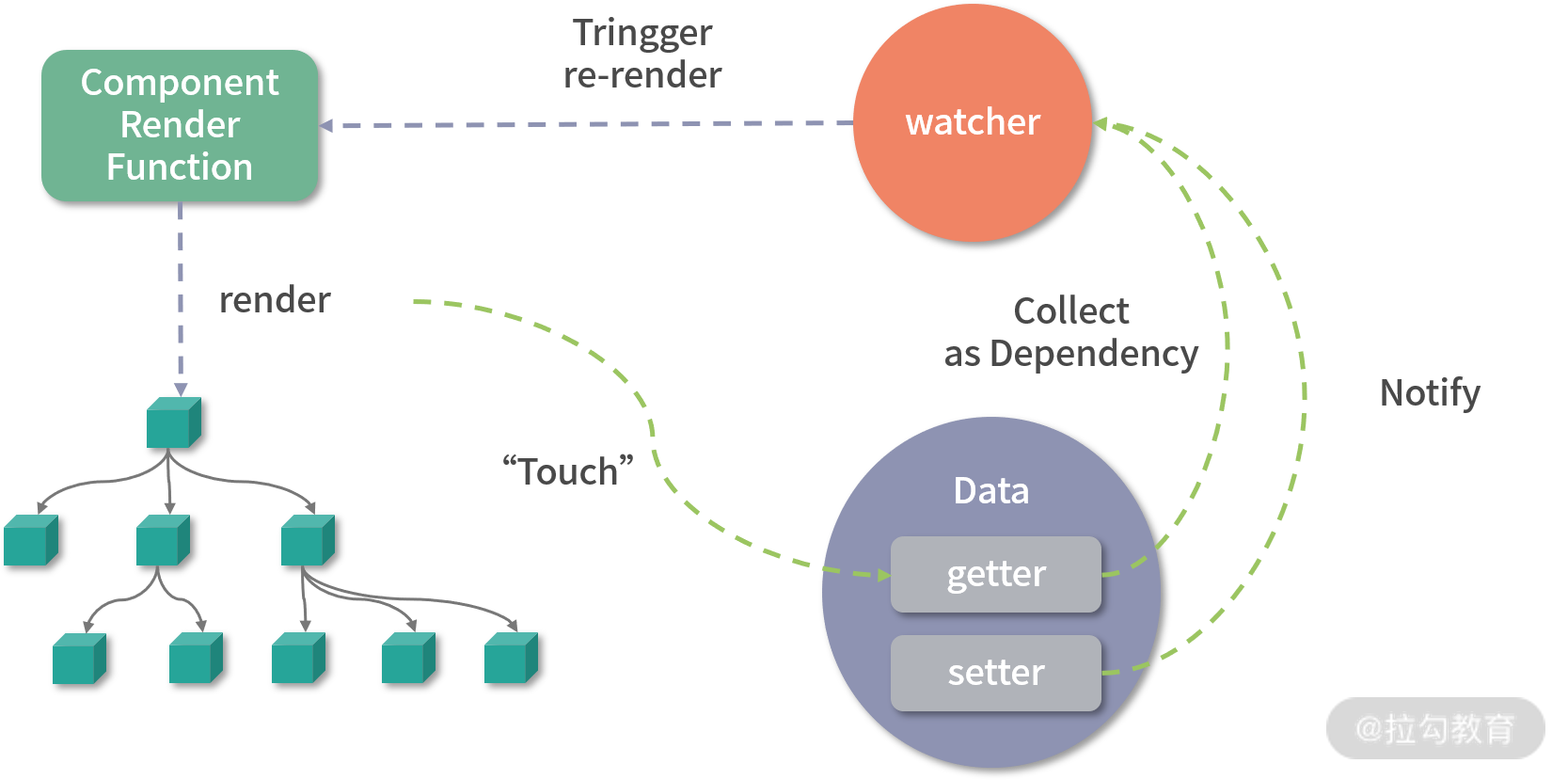
Vue.js 1.x 和 Vue.js 2.x 内部都是通过 Object.defineProperty 这个 API 去劫持数据的 getter 和 setter,具体是这样的:
|
|
此API的缺陷是并不能检测对象属性的添加和删除,还有无法检测到数组的变化。尽管 Vue.js 为了解决这个问题提供了 $set 和 $delete 实例方法,但是对于用户来说,还是增加了一定的心智负担。其次面对嵌套层次比较深的时候,需要将每一层对象都遍历成响应式对象,对性能负担很大。
Vue3.0采用了ES6新的API Proxy:
|
|
Proxy劫持的是整个对象,所以能够监听到对象属性的删除和增加。都是注意的是Proxy并不能监听到内部深层次对象的变化,所以Vue3.0选择了在getter中去递归响应式,这样的好处是只对真正访问到的对象做了响应式。
编译优化
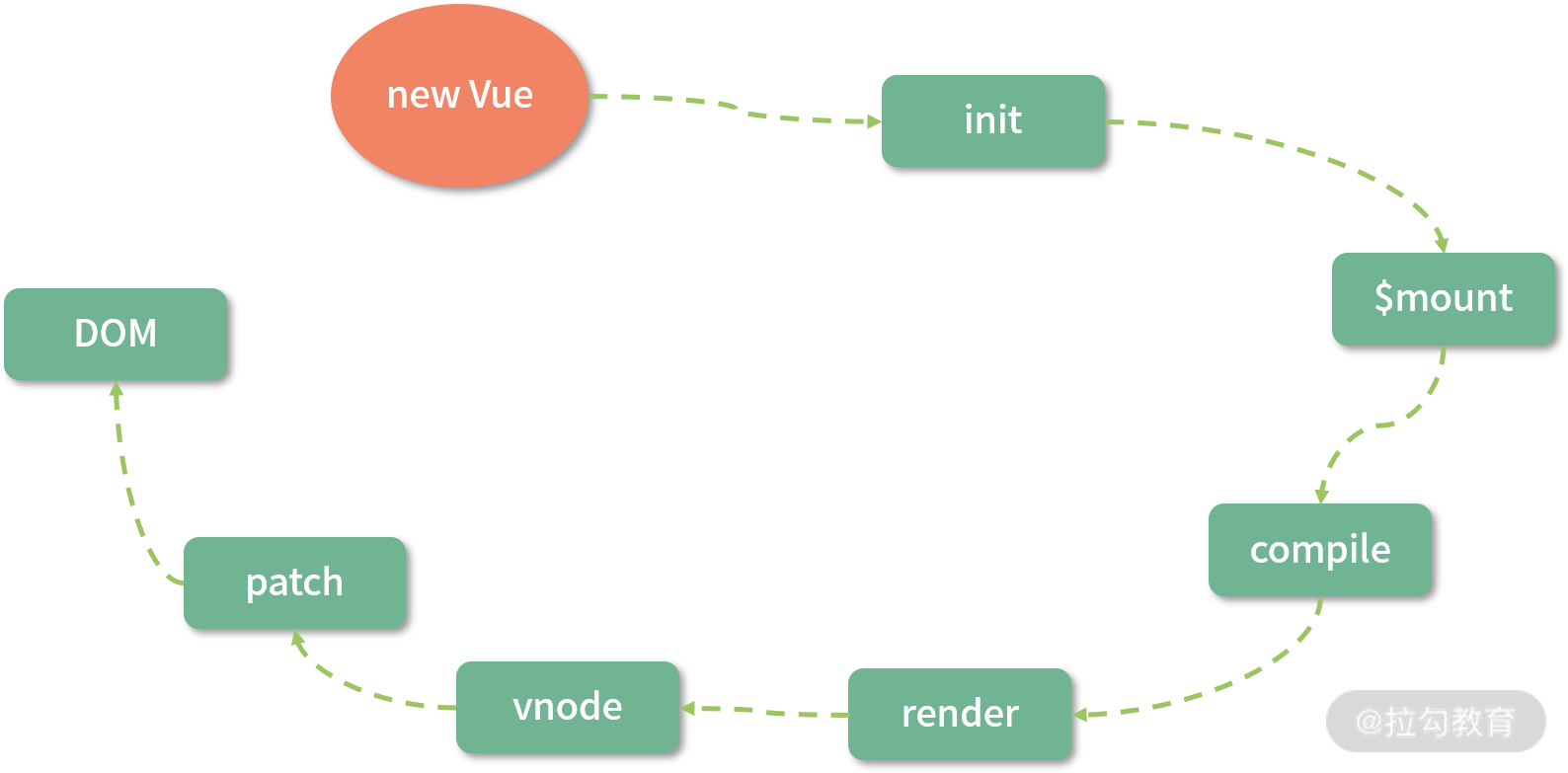
上图是整个vue的渲染流程,一般响应式的过程是发生在init阶段,另外 template compile to render function 的流程是可以借助 vue-loader 在 webpack 编译阶段离线完成,并非一定要在运行时完成。
所以整个vue运行时,除了响应式部分的优化,还可以在耗时最多的patch部分做优化。
通过数据劫持和依赖收集,Vue.js 2.x 的数据更新并触发重新渲染的粒度是组件级的。
虽然 Vue 能保证触发更新的组件最小化,但在单个组件内部依然需要遍历该组件的整个 vnode 树,举个例子,比如我们要更新这个组件:
|
|
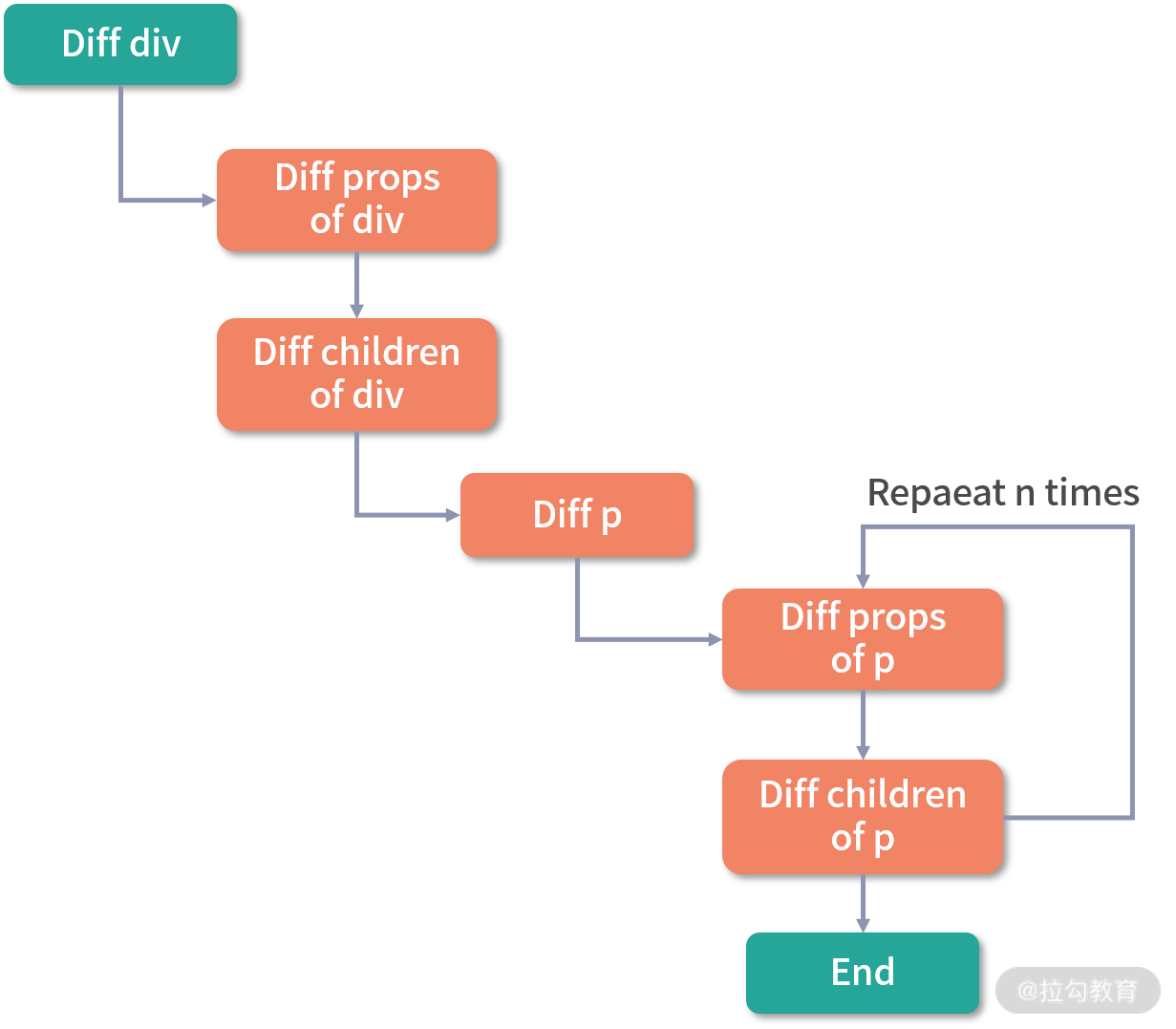
可以看到,因为这段代码中只有一个动态节点,所以这里有很多 diff 和遍历其实都是不需要的,这就会导致 vnode 的性能跟模版大小正相关,跟动态节点的数量无关,当一些组件的整个模版内只有少量动态节点时,这些遍历都是性能的浪费。
Vue.js 3.0 做到了,它通过编译阶段对静态模板的分析,编译生成了 Block tree。Block tree 是一个将模版基于动态节点指令切割的嵌套区块,每个区块内部的节点结构是固定的,而且每个区块只需要以一个 Array 来追踪自身包含的动态节点。借助 Block tree,Vue.js 将 vnode 更新性能由与模版整体大小相关提升为与动态内容的数量相关,这是一个非常大的性能突破,我会在后续的章节详细分析它是如何实现的。
除此之外,Vue.js 3.0 在编译阶段还包含了对 Slot 的编译优化、事件侦听函数的缓存优化,并且在运行时重写了 diff 算法,这些性能优化的内容我在后续特定的章节与你分享。
语法优化:Composition API
逻辑组织

以前在组件中描述组件固定部分需要写在固定的API中,如果是逻辑比较复杂的组件,那么在同一条逻辑线中,就需要进行代码的跳转。采用Compostion API 可以将同一条线的逻辑写在同一块,使代码更加清晰。
逻辑复用
在2.0中一般使用mixins来实现复用,使用单个 mixin 似乎问题不大,但是当我们一个组件混入大量不同的 mixins 的时候,会存在两个非常明显的问题:命名冲突和数据来源不清晰。
采用Composition API的方式写Hook函数:
|
|
然后在组件中引用:
|
|
可以看到,整个数据来源清晰了,即使去编写更多的 hook 函数,也不会出现命名冲突的问题。
Composition API 除了在逻辑复用方面有优势,也会有更好的类型支持,因为它们都是一些函数,在调用函数时,自然所有的类型就被推导出来了,不像 Options API 所有的东西使用 this。另外,Composition API 对 tree-shaking 友好,代码也更容易压缩。
虽然 Composition API 有诸多优势,它也不是一点缺点都没有,关于它的具体用法和设计原理,我们会在后续的章节详细说明。这里还需要说明的是,Composition API 属于 API 的增强,它并不是 Vue.js 3.0 组件开发的范式,如果你的组件足够简单,你还是可以使用 Options API。